
Body language is the number one means by which we communicate emotionally, then tone of voice, followed by words themselves. Computer language, on the other hand, is quite the opposite.
Voice recognition software has been around for some time with “Speakable Items” appearing as the first built-in speech recognition and voice enabled control software for Apple computers in 1993. Dragon was released in 1997 and is still widely used to date.
Today, the goals with voice and gesture recognition software are to enhance immersion with a more natural means of communication. In game play, AI should be able to understand a player’s in game location, what they are talking about, pointing at, looking at, and the action they are performing.
In Japan, AI engineer Gautier Boeda at Square Enix Co. that is behind Final Fantasy, Shadow of the Tomb Raider and more games, is one of the researchers working on these types of interactions.
Kobun, the demo Boeda provided at the Game Developers Conference in SF last week, demonstrates the following: speech recognition, gesture recognition, and a reward based system to train the AI. Just as when we use speech recognition software and correct false outputs, this feedback system customizes a unique user’s experience.
Grammar is also incredibly important to the speech recognition pipeline. AI must recognize parts of a sentence such as the verb, preposition, determiner, adjective and noun to evaluate the object, action, location and the intended result.
Language though, is very abstract. From one language to another there are vast differences in style and structure, pronunciation, expressions and other differentiating values.
In an effort to develop a resource for the clarification of terminology for computer programming, Princeton University released WordNet– a large lexical database of English that groups nouns, verbs, adjectives and adverbs into sets of cognitive synonyms (synsets) that each express a distinct concept. For example, type in any word in their Search, and it will display its various meanings.
To apply this to Kobun, Boeda must go through these lexicons, and manually select the concepts that are relevant to the particular game context. As these programs develop, this process will also become automated. In the meantime, this custom feedback is a part of the machine learning process.
Below, Boeda demonstrates the example of what it means to train the AI to identify the meaning of the word “big” in the context of “a big apple.” The word ‘big” is entered into the lexicon, and then the correct concepts must be selected that are relevant to the particular situation.

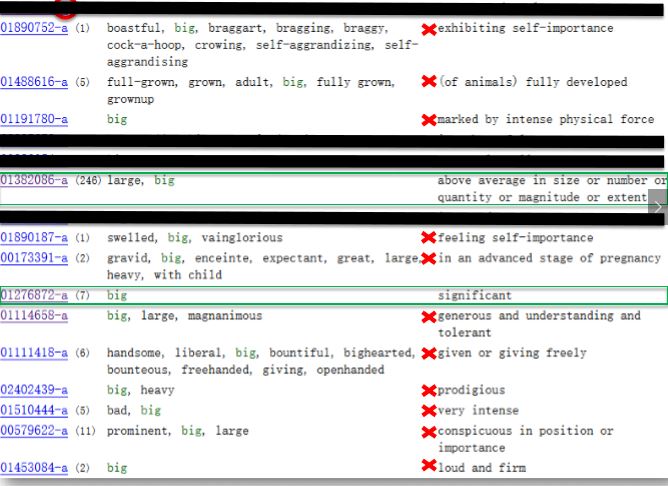
As an end result, the “DNA” of the world is developed for the world of Kobun:

With this example, it’s apparent that speech recognition, let alone adding gesture based interactions, is extremely complex. Homonyms, long and intricate sentences, a player’s unique language and speech patterns must all be taken into consideration for seamless game play and natural interactions.
To combat failure cases, Boeda looks at adding user feedback for the AI to learn, just as in speech recognition software like Dragon, but based on the same method of voice recognition. This includes comments from the AI to the user such as:
- I did not understand your speech
- I did not find what you were talking about
- I understood but I don’t have the ability to execute your request
This is very much like the verbal feedback we use when speaking to one another, and is a major step toward highly effect voice interactions for gaming, especially in immersive environments.
In addition to voice recognition, is gesture based interaction that uses location based information. This includes pointing at objects and locations and using simple instructions to communicate what action is to take place.
There are two main ways to determine this interaction. First, is finger direction or finger position. The second is the direction and position of eyes in relation to the tip of the finger. Boeda indicates research has shown that there are less errors when using the second method that combines finger direction and eye tracking (user POV), although it still highly depends on the specific user case. Using eye-tracking only is the next best result to effectively determine object and location targets.

As a writer, this combination of word, speech and gesture based gamer and AI interaction is fascinating. One challenge that has often been used in technical writing courses is to write instructions on how to make a paper plane. At the end of the assignment, instructions are exchanged and loads of folded paper objects are generated that generally look nothing at all like paper planes.
Even when using eye and finger tracking, instructions such as “go to the left of” or “behind” or “on top of” can still mean many different things based on object orientation and player POV.

Boeda says the next steps in speech and gesture based recognition for player and AI interactions is to work with multiple player situations, and to support a greater variety of statements that include questions and empathy statements that the AI can react to. As seen in the example with Kobun, the creature displays empathy based expressions and actions that are context and reward based.
Already immersive technology enables us to sometimes forget that the virtual spaces we occupy aren’t actually real. With enhanced AI and user interactions and natural expression compared to clunky buttons and menus, our sense of what is real and what is virtual may also have to be redefined in ways that are user and context based.
By Anne McKinnon
Instagram | Twitter | LinkedIn
